


Rube Goldberg, Cloud Architect
February 26, 2024
Important: I originally published this article on Medium. If you have a Medium subscription, please consider supporting my writing by reading it on Medium.
I started my career in Linux in the early 2010s during a liminal time in systems administration. DevOps, Site Reliability Engineering, and Cloud Engineering were all disciplines advocating for drastic changes in the way systems and application teams worked together, often with debatably sound promises. Books were written, job titles ballooned, and myriad methodologies rained down from the technological heavens to improve organizational velocity and software quality.
While the claims may have been dubious, many of the underlying ideas made a lot of sense, especially at face value. Even upon closer examination, there was room for debate but the concepts were often solid. DevOps promised a nirvana of ending the “throw it over the wall” mentality that had dominated software development. Cloud engineering promised to “turn CapEx into OpEx”, a phrase that you will never hear anymore but made sense (to some career-minded people) at the time. Site reliability engineering argued that maybe we should actually track some metrics and aim to optimize them. While we could quarrel over the specifics, many people agreed that the ideas made sense, even if their implementation was…difficult.
I’m less convinced of the sensibility of the modern technology frenzies. My early jobs primarily focused on getting things done. The priority, above all else, was to deliver. It wasn’t always perfect, and this approach frequently meant that we failed to devote the necessary time to improving the scaffolding (processes, automation, etc.) to support work. However, the value that I delivered was usually easy to quantify: build some servers, spin up some environments, automate an account creation process, and so on. Note that delivering isn’t the same as shipping new things. It’s equally possible that “getting things done” involves building a new environment for a product or upgrading an existing environment.
Webscale Processes
At some point, I started working with an organization that billed itself as a DevOps-focused team. One of my early projects was to assist with some trivial activity to deploy a cloud monitoring solution into our single AWS account. I can’t remember the specifics, but for the sake of this discussion, I’m going to use Cloud Custodian as the chosen product.
If you’ve never worked with it, Cloud Custodian is an awesome tool that monitors cloud resources and can automatically “clean up” a cloud account: deleting resources, turning off VMs, and other actions to promote good cloud hygiene. The deployment model is pretty straightforward: it’s a simple application that can run in a VM or container. Policies are written as code and ideally managed using Infrastructure as Code (IaC) best practices.
I vividly remember the conversation during one of the early planning discussions for this project:
Me: “OK everyone, we can just deploy Cloud Custodian as a scheduled Lambda function, and then document that relatively simple installation procedure. Then, we can automate the process of loading the policies from a Git repo, and we should be all set.”
This seemed pretty reasonable in the hierarchy of “things to automate.” Deploying Cloud Custodian is a one-and-done activity: you install it and then you kind of forget about it. Loading policies is an ongoing task and is ideal for automation. We only had a single AWS account to worry about, so we didn’t have a horizontal scaling consideration.
Someone who had been there awhile chimed in: “Well, we need to also automate the process of deploying Cloud Custodian itself.”
Ah, I was still new here. At this place, everything had to be automated. The “everything has to be X buzzword” is a pretty common phenomenon these days, often culminating in the comical “everything has to be deployed as microservices” architecture that involves a spaghetti of interconnected services to support a Javascript app for a company with 5 paying customers.
So, what did we end up doing? Well, the most reasonable thing you can think of for a task that you would only perform once. We automated it to the absolute extreme. We took the following boring, non-webscale process:
- Create an IAM role
- Create a Lambda function containing the Cloud Custodian code
- Deploy the function
- Document the process
And transformed it into this much more Web 7.0 series of tasks:
- Set up a new repository
- Configure all of the necessary permissions on the repository
- Write
code (Terraform? Python? I can’t remember) to create the desired IAM role and Lambda function
- Troubleshoot the code as needed
- (Future consideration that nobody cares about) Update and maintain the code as needed when AWS decides that they should reinvent IAM for the fifth time.
- Write a build pipeline to package this code into a release artifact
- Troubleshoot the pipeline. Ask anyone who has ever written a CI/CD pipeline and they’ll tell you about the nightmare that is pipeline debugging.
- Write a deployment pipeline to deploy the code into Lambda.
- Troubleshoot the pipeline. Ask anyone who has ever written a CI/CD pipeline and they’ll tell you about the nightmare that is pipeline debugging.
- Ensure the pipelines have all of the necessary cloud credentials to talk to AWS
- (Future consideration that nobody cares about) Occasionally rotate the authentication material
- (Future consideration that nobody cares about) Rip and replace the authentication mechanism entirely, because nothing is as temporary as a cloud authentication technique.
This is an incredibly common approach to building systems today. The “automation first” bug results in an abject insanity in which engineers spend hundreds of hours building automation or architecture (looking at you, microservices) to optimize for a problem that doesn’t exist right now, and maybe never will exist. Each time I look at an insanely complex build pipeline or a mapping of microservices, I can’t help but think that Rube Goldberg would have made an extraordinary cloud architect.
Below is an image of a Rube Goldberg machine to clean hats. It probably resembles a service call graph for your microservice application:
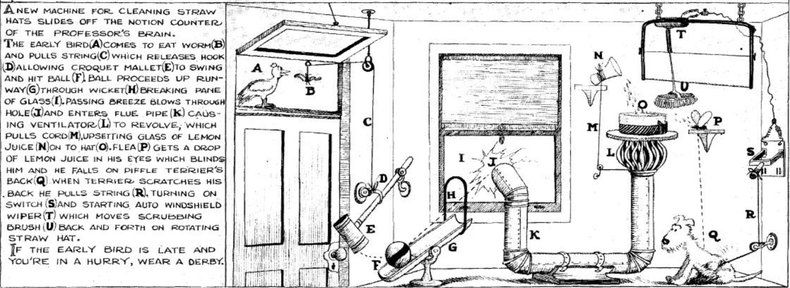
But, but…
I can see the nervous shifting in the audience and, peering inside your mind, I can even hear the objections bubbling under the surface of the WebScale psyche:
“But Anthony! If you code and automate it once, you can deploy it into hundreds of AWS accounts! If you start with microservices, then you never have to worry about scale!”
This encodes the crux of most modern “patterns”: premature optimization has become a best practice. Rube’s hat machine could probably clean lots and lots of hats, but at what cost? We consistently fail to consider the maintenance burden of these approaches:
- At some point, the code (Terraform module, whatever) will be out of date.
- At some point, the pipeline definition file will be out of date. A particular container image might be deprecated, pipeline syntax may change, or many other potential maintenance issues.
- At some point, the method of authenticating with the cloud provider will change.
- In reality, maintaining complex systems is…well, complex.
We’ve become very hand-wavy about maintainability objections, favoring some dubious and poorly quantified benefits (it’ll scale!) over very real drawbacks that are often staring us right in the face (the Kubernetes version is already out of date and in-place upgrades probably don’t work). This fallacy permeates human thought (there’s probably a name for it). Just think of your friend who bought a $3500 camera because they enjoy amateur photography and “maybe someday they’ll need the better camera if they start doing paid gigs.” This isn’t even making long-term tradeoffs for short-term gains, or vice versa. It’s making short and long-term tradeoffs (maintainability, complexity, etc.) for gains that may never even materialize (scalability, repeatability, etc.).
Implications
I know this all sounds a lot like a classic, crusty admin complaining about the latest fashions. But I think these shifts have real negative implications for our industry. Whether it’s the vendor-focused tarpit of the AWS Well-Architected Framework or the mind-numbing complexity of needing a half dozen microservices to run an entire Kubernetes cluster to deploy a web app, the reality is that it’s increasingly difficult to build systems that can generalize. Much like the Hotel California: you can check out anytime you want, but you can never leave.
You’re never leaving the public cloud once your app to send an email requires an API-binding that drops a message into a queue, which is picked up by ephemeral workers in a function-as-a-service offering to customize the email with some metadata from the cloud provider’s fancy NoSQL database and then finally shoot the message out of their email service. That nicely-decoupled microservice application is now stuck to Kubernetes like Ralphie’s tongue in A Christmas Story. We’ve lost the ability to write portable applications, and the irony that most organizations are now talking about “multicloud” is entirely lost on us.
It’s also been my anecdotal experience that so many people have lost a robust understanding of how underlying technology works. Containers are viewed as a magical, mysterious system instead of what they are: processes running on a system. Troubleshooting a slow database query is a dark art, reserved only for the chosen few. Many will argue that this is the goal: let someone else worry about all that operational nonsense so that your organization can achieve the nirvana of NoOps. Except this is never the case for non-trivially sized organizations. I distinctly remember working with an organization to outsource a hosted NoSQL datastore to a cloud provider’s SaaS, only to desperately need all of the previous in-house expertise to troubleshoot performance issues, because the vendor certainly couldn’t explain the behavior of their own offering.
As we lose this ability to truly reason about the underlying technology, we also compound the issue with the inability to hold a system’s state in one’s mind. This is already hard enough because of the microservices zeitgeist, and we occasionally see organizations move away from them because of this. It’s tempting to believe that sufficient levels of abstraction remove the need to hold the entire state of a system in one’s mind. However, this is extremely difficult to achieve and doesn’t jive with the “dump code into main and hope the unit tests work” philosophy of modern software development. Projects that do manage to maintain robust abstractions that the user is barely aware of, such as the Linux kernel, move glacially slowly and methodically when compared with a modern web app. To be clear: this isn’t a criticism or affirmation of either approach. Rather, an observation that it’s very difficult to discuss robust, long-term stable abstractions when the product team is already porting the entire codebase to Rust because someone read that it’s faster over the weekend.
We also add an enormous amount of operational toil, all in a hilarious effort to remove operational burdens. Remember how everything had to be automated? How this resulted in organizations with giant Jenkins environments with Lovecraftian pipeline definitions and artisanally maintained Makefiles to deploy even the simplest of applications? Remember screaming at your computer “Why the **** can’t I just SSH to the server and edit the file?” because of the Sisyphean config management system you put into place? Well, that just keeps getting worse as we pile on a dump truck of vendor-specific services. Those cloud provider APIs will change and do. And, instead of solving business problems, someone has to constantly maintain this stuff.
The Troubleshooting Conundrum
Ease of troubleshooting is unbelievably important, and so it deserves a dedicated section. I’m convinced that anyone who doesn’t emphasize simplicity in troubleshooting above everything else has never actually troubleshot a deeply complex issue. This is a hill that I’m willing to die on. If the solution you come up with is hideously complex to troubleshoot, then it probably isn’t a good solution. This might not be your fault: you might be playing within the technical and organizational limits imposed by your organization. If everyone is doing microservices, then you’d be stupid to think that something as simple as sending an email can be done in a few hundred lines of code, instead of 20 interconnected JSON web services.
Providing tooling around troubleshooting is helpful, but it isn’t sufficient for the most complex issues. The underlying infrastructure must be simple enough to allow for deep introspection when the tools fail. This statement becomes more true as the abstraction becomes leakier, and most modern “cloud native” technologies are like a melting polar-ice cap of leakiness, waterboarding unsuspecting junior engineers in promises of simplicity while spewing incomprehensible error messages into logging channels that require a PhD in Cloud (and $10k in cloud-specific logging credits) to even uncover.
This phenomenon is comically apparent in the “cloud native” communities, where your average, officially supported cloud architecture diagram is nearly indistinguishable from a Rube Goldberg cartoon:
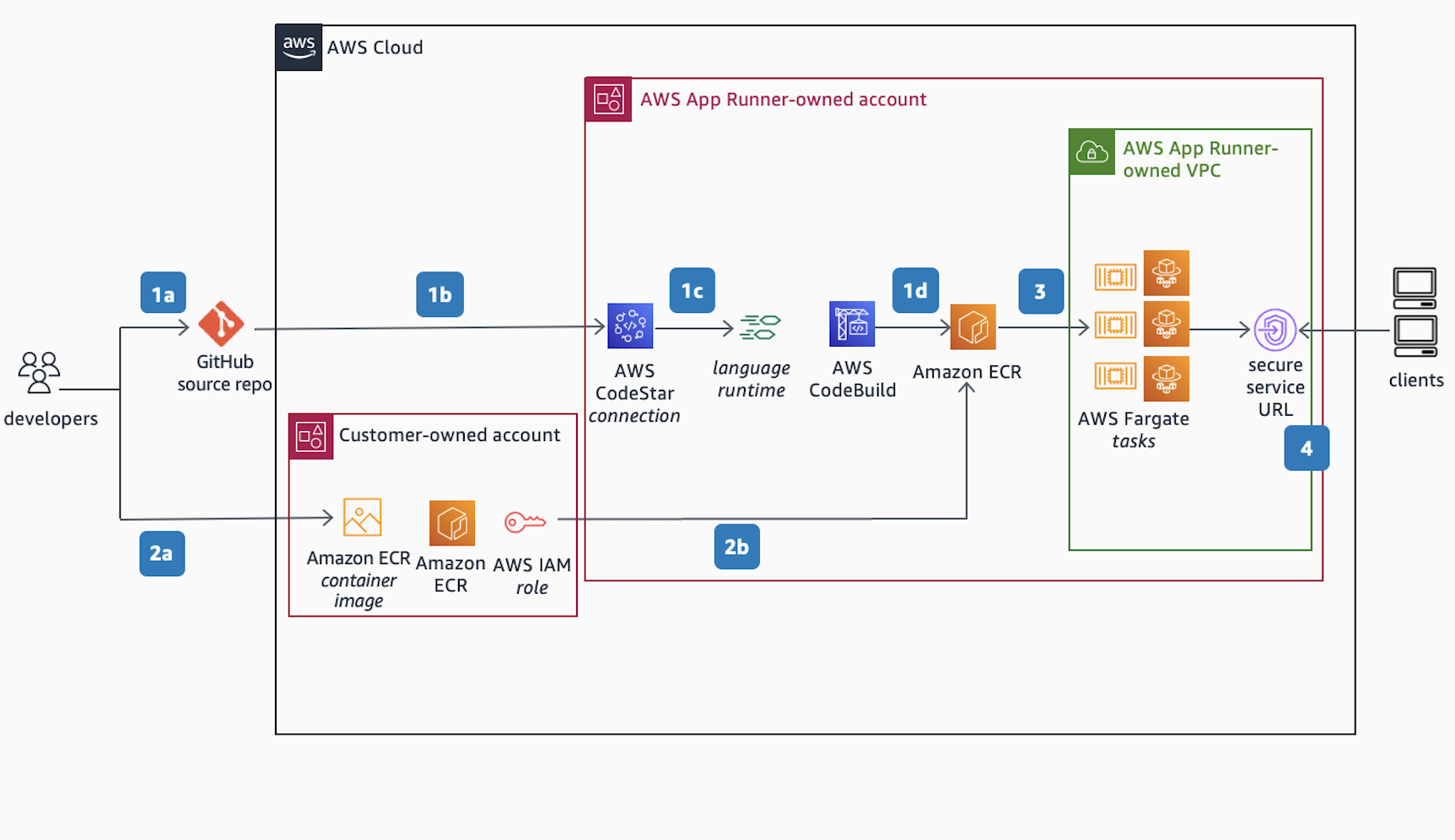
Want to host a simple website with user signup and login? Well, what you actually want to do is build a collection of 100 functions and run them in a functions-as-a-service platform, front-ended by an opaque cloud load balancer that performs layer 7 load balancing to direct traffic to the appropriate backend function based on A/B testing. Store the results in an infinitely scalable NoSQL database. Don’t send the users emails. Drop registration requests into a queue and have another service process them, dropping messages onto a different queue for a notification service to handle. Store all static assets in object storage, also front-ended by a global CDN for maximum speed (you’ll appreciate that speed when serving a 10MB single-page application). Ignore the fact that you don’t even have any customers yet. Architect now for future growth.
Seriously, try to troubleshoot these designs. Cloud-provider logging is universally horrendous and typically very expensive. Once your requests begin interacting with more than a single cloud service, you’re screwed. Whereas before you could tail a log file to debug an issue, now the service you’re using might not even log the data you need to troubleshoot. Good luck!
Wrapping Up
The average company used to effect rapid growth by writing a monolithic app, throwing it onto a few servers, and addressing problems as they came up. You could still build with future growth in mind, but the idea that a trove of complexity was necessary for a simple application was virtually unheard of. Now, we’re faced with a rat’s nest of vendor lock-in and hundreds of hours spent learning new services (and probably introducing production bugs due to lack of knowledge).
So what’s my point? I’ve thought about that a lot as I’ve written this increasingly long, rambling diatribe. My goal isn’t to scare anyone off the cloud, or Kubernetes, or (certainly not) automation. My intent is simply to point out this increasingly disturbing industry trend: Implementing ${TECHNOLOGY} has become an end in itself, a distraction from the true business goals that organizations ultimately have. And I think that’s deeply unsatisfying from an engineering standpoint: building simple LAMP-stack webservers isn’t the most satisfying job in the world, but there’s something concrete about it. We spend so much time in operations worrying about scale || growth || efficiency || performance that we forget to actually build the product and get something out of the door, and I think that we burn out because of it.
So go build something today. Next time someone tells you that a git repo with a pipeline and automated build step complete with per-commit artifacts is necessary to create a one-time S3 bucket, tell them to go pound sand. Write a wiki article, and go do some real work for a change.
Previous article: On Systems Administration